Aug 31 2008
Testing My SDBlogger Yahoo Pipe
I’ve been learning Yahoo Pipes to see if I could add more info, specifically the name of the blog, to the SDBlogger Twitter feed that itself is fed from a FriendFeed RSS feed.
Follow my progress at http://twitter.com/declantest
This all started when Matt Browne set up a FriendFeed room for SDBloggers, a gathering of rss feeds from local bloggers’ sites. Matt then set up an RSS to Twitter feed using Twitterfeed.com that took the RSS from the room and posted it as the Twitter user SDBloggers. By following this user, people could get a tweet telling them that something new had been posted on any of the blogs in the room.
Now, there are over 50 different blogs in the room, any of which could alert Twitter that it had a new post. The problem I had was that the tweet looked like this:

I couldn’t tell by looking at the tweet which blog it was referring to. The “(via Blog)” part of the title was generic and the same on every tweet, regardless of the sender. I mentioned to Matt that he should change that. Manager that he is, he tasked me with looking into how to do it… 😉
I knew from the raw HTML on the Friendfeed site that the name of each entry’s blog was available. And when I looked at the RSS feed provided by Friendfeed, all the parts where there. The item.content was made up of a lot of HTML and included some consistent text – specifically “an entry from” followed by an “a” tag that changed per entry, then the closing “a” tag. I just needed to parse the RSS, rip the blog name out of item.content, then replace “(via Blog)” with “(via ” + real blog name in the item.title.
At first I started with a perl script I found called RSS2Twitter. After spending a good part of a day off re-learning perl for the 17th time, I said, “heck, let’s learn something new…” and started playing with Yahoo Pipes.
I’m technical, but I’m not a programmer, so I usually start with some example and hack a piece of code until it does what I want. The initial problem I had with Pipes is that I wasn’t sure what context I was in. I knew I wanted RSS in and modified RSS out, but I was confused how to go about it. I looked at a couple examples and figured out I needed to start with a Fetch Feed object, and to stuff the Friendfeed RSS URL into it. The debug window was a bunch of help, showing me what the output of each object was as I clicked on Refresh.
So, now I had a list of RSS entries. I knew where my pieces were, I just couldn’t figure out how to extract them. I Googled “pipes tutorials strings” and the first link was from Daybarr.com and helped a ton. I needed to copy the item.content to a temporary variable so I could do some work on cutting it up without hurting the original item.content. From Daybarr’s page, I saw to use the “Rename” object and invoke the Copy As method (not sure that’s proper programmer talk) to replicate the value of item.content’s to my new variable called content_holder.
Here’s where it really gets ugly. I hadn’t touched regular expressions in a long time, but I’d need one to isolate the blog name from all the HTML. Another few Googles gave me some tutorials, and I settled on one from Apple. The intro mentioned Reggy, a regex validator that lets you write ugly little regex code in the top pane, paste some text into the bottom pane, and see the results in real time. It really helped:
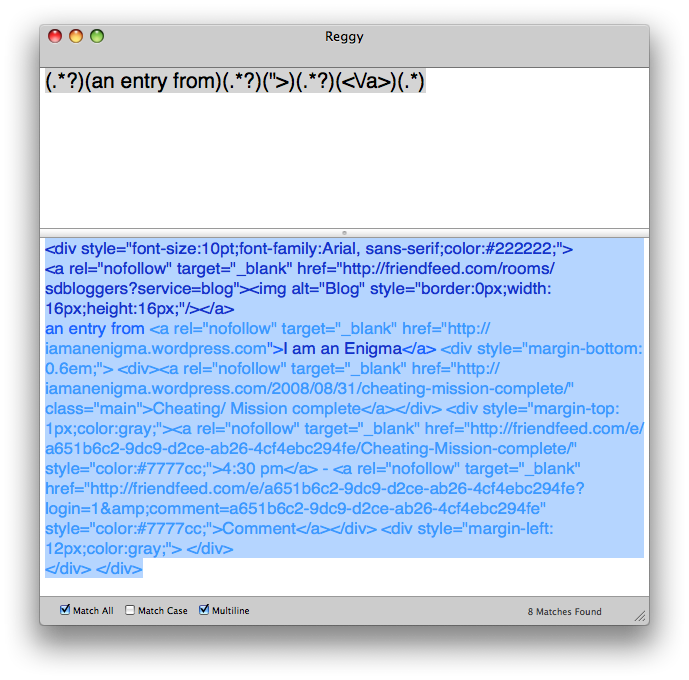
You can see the regex I used in a Pipes Regex object in the top pane of Reggy above. What I’m doing is finding whatever is in that space, shoving it into the regex variable $5, then replacing the whole of content_holder with $5. It seems kludgy, and it probably is, but it works. 🙂 I use another line in the regex object to strip the generic “(via Blog)” text from the item.title.
Believe it or not, the next Pipes object was the hardest to get my head around. It helps a lot to cursor over an object’s connection points to see what input and output is expected and delivered. I did this for a long time before I read Daybarr’s loop example. The Loop objects consumes items and lets you perform operations on them individually, as opposed to the whole stream of items at once. The Loop object is modular in that it allowed me to plug a String Builder object into it. Once I understood that I had access to each item’s fields, with the blog name stuffed into my content_holder variable, all I had to do was add string parts to the String Builder in the order I wanted them to be concatenated. The last little trick in the Loop object was to assign the results to item.title.
I’m not really clear why everything else just gets passed through untouched, but that’s the context problem I was struggling with. Once I stopped worrying about all the details and concentrated on the parts I knew I wanted to change, I made a lot of progress. It’s not how I normally work. Understanding the boundaries of a system usually helps me know which way to start a solution. Assuming that “it’ll all be ok” doesn’t occur to me naturally.
One last Regex object to strip the content_holder variable out of the resulting RSS, and it’s all clean.

I fed this to Twitterfeed.com and it fails validation, BUT after waiting the 30 minute delay, I got results!
Here you can see the name of the blog (in this case it’s mine for testing) right in the tweet!

Ok, it doesn’t seem like that big of a deal, but I learned something new and now I have a blog post I can go back to when I forget it all! 🙂
My regex is probably flawed. If there were a blog with “an entry from” in the title, I bet it would fail. And I didn’t use any “[” or “^” so I’m not very cool.
How would you have gone at this problem differently? How have you learned Pipes?